In our systems, most business actions require changes across multiple contexts. How can we keep these contexts consistent?
Let’s look at an example and analyze potential problems and solutions.
Imagine a logistics application, where drivers can earn money by completing jobs. We’ll focus on two modules: Documents and Payment. For every job, the system requires two documents to be uploaded and then accepted. After both documents have been accepted, a driver receives compensation for their work.
Accepting a document looks like this:
defmodule Documents do
def accept(document, job_id) do
Repo.transaction(fn ->
{:ok, _} =
document
|> Ecto.Changeset.change(accepted: true)
|> Repo.update()
:ok = Payment.handle_document_accepted(job_id)
# a bunch of other logic
end)
end
end
defmodule Payment do
def handle_document_accepted(job_id) do
if Documents.both_accepted?(job_id) && not_paid_yet?(job_id) do
:ok = pay_the_driver(job_id)
end
end
end
We can see that it is in a transaction that guarantees data consistency. The functions are idempotent so double-clicking and triggering this interface twice for the same document doesn’t cause any problems.
What’s wrong?
Although it looks correct at a first glance, there are some hard-to-see problems with this code.
The diagram below shows the scenario which may occur when a user clicks the acceptance button one by one, initializing two transactions:
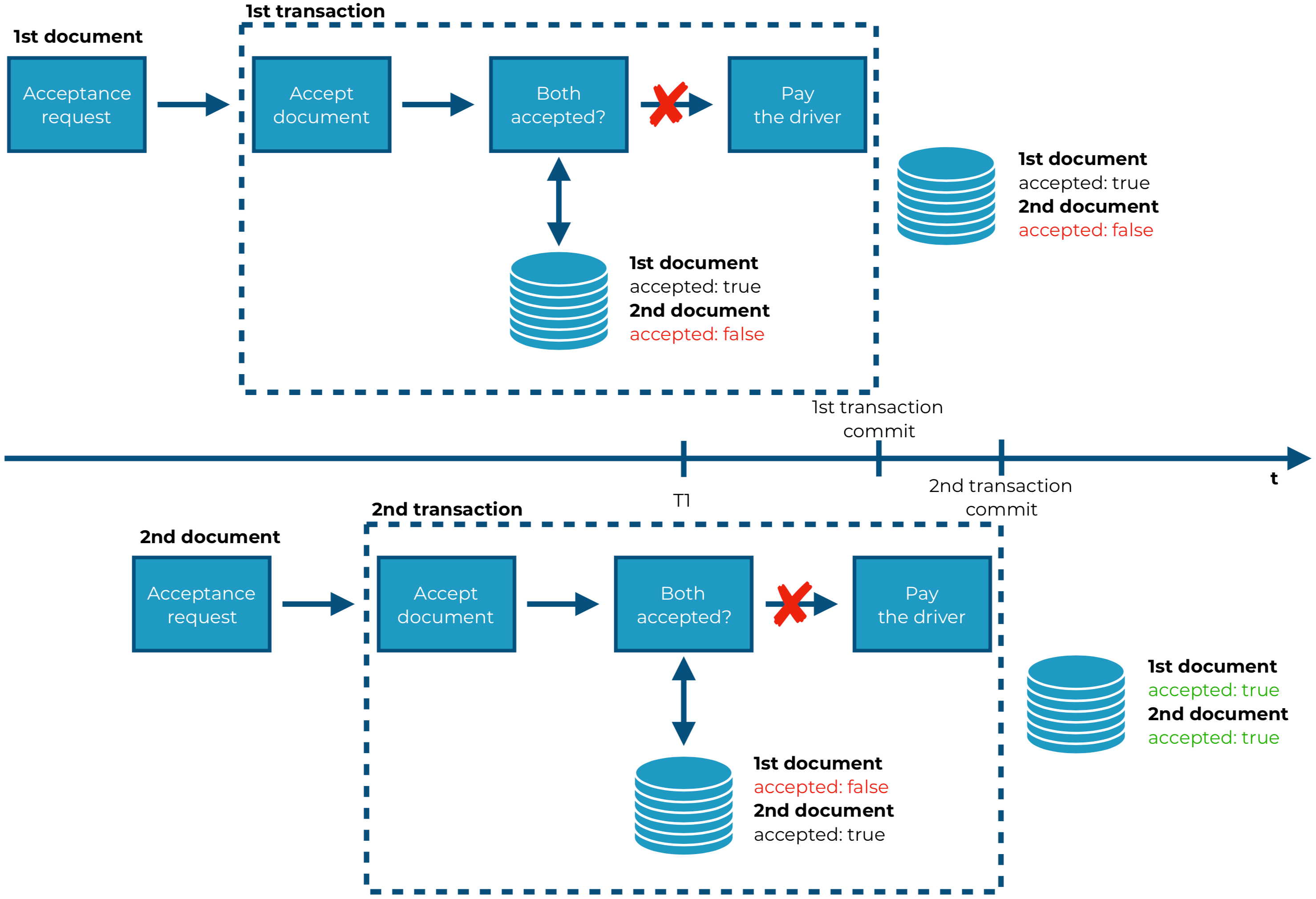
The problem occurs when someone clicks the acceptance button one time after another within a very short period of time. In the beginning, both transactions see the same database state. While the first document is being accepted and then verified if both are accepted, there is only one confirmed document. This is fine because that’s a document which has just been accepted in this transaction. Let’s look at the second transaction at the moment T1 (it is marked on the diagram above) when the code checks whether both documents are accepted. When looking at the timeline, we can notice that at that moment both documents should be accepted. Unfortunately, the first transaction hasn’t been committed yet, so the changes in the database are not visible in the second transaction. Documents.both_accepted?/1 function returns false and the driver doesn’t get paid for their job. After all, when both transactions finish, the state of the database indicates that both documents are accepted.
How to solve this?
Let’s try to think about the real world for a second. In the real world, employees don’t get their compensation instantly. A driver finishes their work, uploads documents and then a shipper accepts these papers. From a driver’s point of view, this isn’t a synchronous process. Thus, we can imagine that after the finished job, this information is delivered to the payment department which, in a specific moment, pays the compensation.
The one way to avoid this inconsistency is to, firstly, create a function, which moves accepted documents to the place where they’ll be awaiting payment:
defmodule Documents.Accepted do
use Ecto.Schema
import Ecto.Query
schema "accepted_documents" do
field(:job_id, :binary_id)
field(:document_id, :binary_id)
end
def handle_document_accepted(job_id, document_id) do
%Accepted{
job_id: job_id,
document_id: document_id
} |> Repo.insert()
end
end
So now, our Documents module looks as follows:
defmodule Documents do
def accept(document, job_id) do
Repo.transaction(fn ->
{:ok, _} =
document
|> Ecto.Changeset.change(accepted: true)
|> Repo.update()
{:ok, _} = Documents.Accepted.handle_document_accepted(job_id, document.id)
# a bunch of other logic
end)
end
end
As we have all the accepted documents kept in one place, we can create now a worker which will fetch all these documents and pay drivers:
defmodule Payment.Worker do
use GenServer
@interval 10 * 6000
def start_link() do
...
end
def init() do
Process.send_after(self(), :work, @interval)
{:ok, %{interval: @interval}}
end
def handle_info(:work, state) do
Repo.transaction(fn ->
Documents.Accepted.fetch()
|> Enum.map(fn %{job_id: job_id} ->
:ok = pay_the_driver(job_id)
job_id
end)
|> Documents.Accepted.delete_paid()
end)
Process.send_after(self(), :work, state.interval)
{:noreply, state}
end
end
Worker is run asynchronously every 60 seconds and fetches job_ids if both documents are accepted. If all the drivers from those jobs are paid, accepted documents are deleted as they are kept there only for payment purposes. It is worth noting that function pay_the_driver/1 is idempotent to make sure that no driver is paid twice for the same job.
This makes the modules less coupled in terms of operational and temporal coupling. So far, functions from Documents and Payment modules have had to be executed in a certain order and at an appropriate time. By making the Documents module decoupled from the side effects in other contexts, we make it far more extensible and easier to work with.
The result? Less error-prone code. More understandable. Less coupled. More coherent.
The lesson we can see here is that when modeling our code, we should follow the way the real world works. In the real world, we are used to eventual consistency, so we shouldn’t be afraid of it in our software.