Migrating live data is risky. Let’s analyze the example below to see why.
Each year, triathlon races are held in many countries. Triathletes from around the world can sign up for one of 4 distances.
defmodule Triathlon.Race do
use Ecto.Schema
schema "triathlon_races" do
field :limit, :integer
field :distance, :string
# a bunch of other fields
end
def sign_up(race_id, user_id) do
Repo.transaction(fn ->
race = fetch_exclusively(race_id)
case any_entry_available?(race) do
true -> add_participant(race, user_id)
false -> {:error, "All entries have been sold out."}
end
end)
end
defp fetch_exclusively(race_id) do
Race
|> where(id: ^race_id)
|> lock("FOR UPDATE")
|> Repo.one()
end
defp any_entry_available?(%Race{
id: race_id,
limit: limit
}) do
signed_up_number = fetch_participants_number(race_id)
limit > signed_up_number
end
end
defmodule Triathlon.Participant do
use Ecto.Schema
schema "triathlon_participants" do
field :user_id, :integer
field :race_id, :integer
# a bunch of other fields
end
end
Notice that every time someone tries to register, we have to fetch the participant count. We also have to use a lock to prevent race conditions. This can be slow when many people are trying to register at the same time.
To solve that, we decide to add the entries_left field.
defmodule Migrations.AddCounterCacheOnTriathlonRaces do
use Ecto.Migration
def change do
alter table(:triathlon_races) do
add :entries_left, :integer
end
execute("""
UPDATE triathlon_races
SET entries_left = triathlon_races.limit - participants_subquery.number
FROM (
SELECT race_id, count(*) AS number
FROM triathlon_participants
GROUP BY race_id
) AS participants_subquery
WHERE triathlon_races.id = participants_subquery.race_id;
""")
end
end
While signing up for a race, we can check left entries based on the triathlon_races table. When a user successfully registers, the number of available entries decreases.
defmodule Triathlon.Race do
# a bunch of other logic
def sign_up(race_id, user_id) do
Repo.transaction(fn ->
race = fetch_exclusively(race_id)
case any_entry_available?(race) do
true -> add_participant(race, user_id)
false -> {:error, "All entries have been sold out."}
end
end)
end
defp any_entry_available?(%Race{entries_left: entries_left}) do
entries_left > 0
end
defp add_participant(race, user_id) do
Race
|> Ecto.Changeset.change(%{
entries_left: race.entries_left - 1
})
|> Repo.update()
:ok = Participant.add(new_race, user_id)
end
end
We made the Race and Participant modules less coupled in terms of operational and temporal coupling. What’s more, it’s worth noting that available entries are the crucial part of the business logic. That’s why it’s good to keep them in the Race module.
Time to deploy!
What will happen if we deploy both the migration and the new code?
Once it is deployed to the production, our server runs the new code with the new migration which is run in a transaction. It means that until the entire process of the migration is finished, the changes entered by the migration are not visible by the system.
What if the table that we want to update contains thousands of records? This process can take several minutes then. Since the migration does UPDATE on the triathlon_races table and the fetch_exclusively/1 function does LOCK FOR UPDATE, the registration process will wait until the lock can be acquired. It means that users won’t be able to register for a race at the time.
How to guarantee a zero downtime deployment?
One way is to implement this process in four steps. Deploying each of them separately to production:
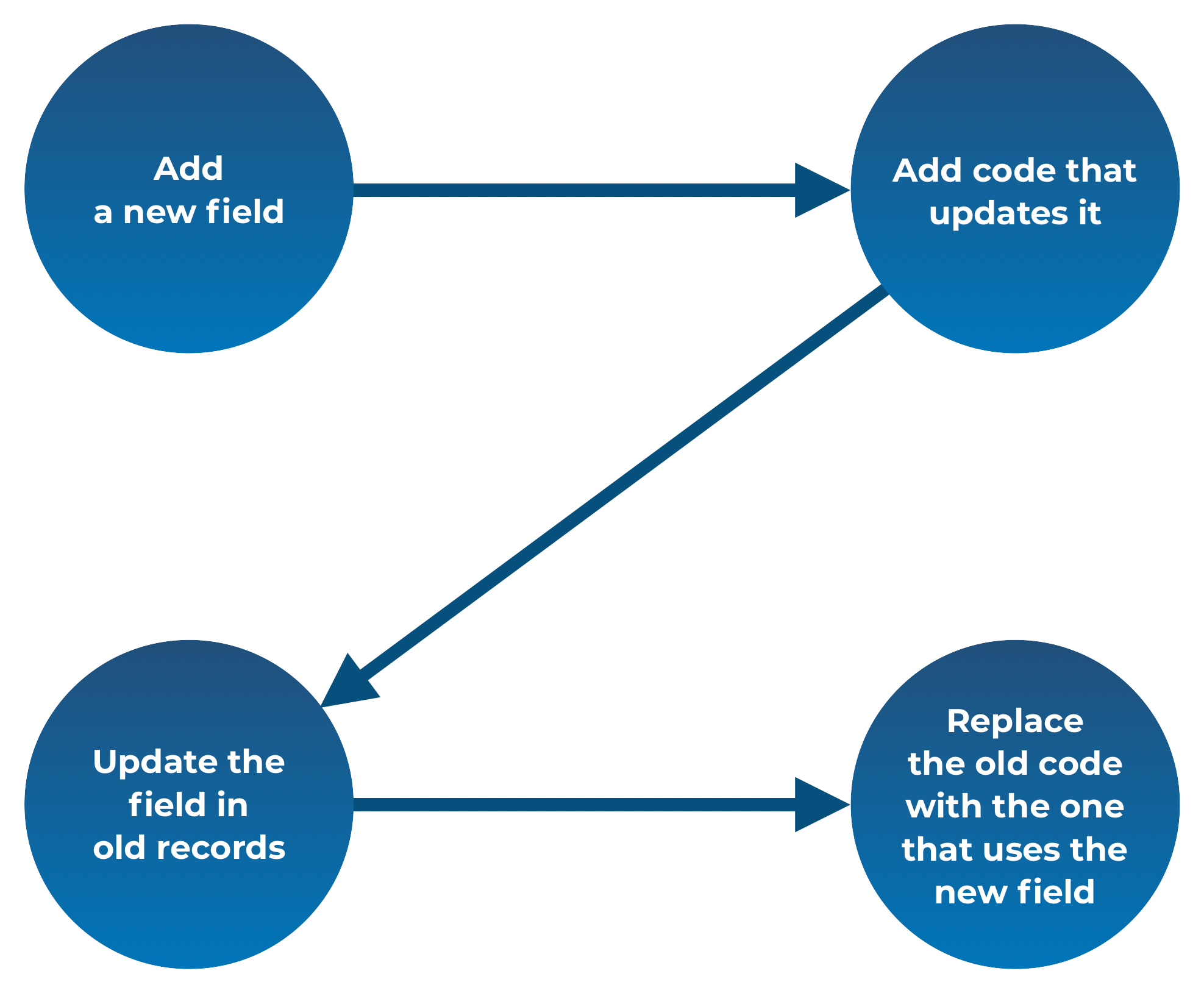
- Migration which adds the entries_left field.
- Add code which:
- sets the entries_left field while organzing a race.
defmodule Triathlon.Race do
# a bunch of other logic
def organize_race(%NewRace{} = cmd) do
%Race{
# a bunch of other code
entries_left: cmd.entries_left
} |> Repo.insert!()
end
end
- during the process of signing up, updates the entries_left field only for the newly created races. The old races will have this field nil so we can skip all such cases.
defmodule Triathlon.Race do
# a bunch of other logic
def sign_up(race_id, user_id) do
Repo.transaction(fn ->
race = fetch_exclusively(race_id)
case any_entry_available?(race) do
true -> add_participant(race, user_id)
false -> {:error, "All entries have been sold out."}
end
end)
end
defp add_participant(race, user_id) do
if new_race?(race) do
Race
|> Ecto.Changeset.change(%{
entries_left: race.entries_left - 1
})
|> Repo.update()
end
:ok = Participant.add(new_race, user_id)
end
defp new_race?(%Race{entries_left: entries_left}) do
not is_nil(entries_left)
end
end
- Run code which updates the entries_left field in the old records.
- After performing points 2 and 3 the data are up-to-date and we can already use them in our logic. So we can replace the old code with the one that uses the entries_left field instead of fetching participants number from the database each time.
Do we really need step 2?
Without this step we assume that none would register between the process of updating the entries_left field (see step 3) and replacing the old code with the new one (see step 4).
If someone signed up in that specific moment, we would have a race with the entries_left field equal nil. It means that any_entry_available?/1 function would return nil for this race, although the system wouldn’t know how many available entries there are.
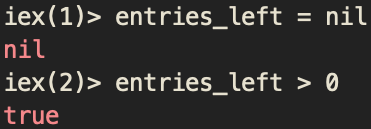
Such a scenario silently destroys our data consistency, because a user can register for a race which has all entries sold out.
Summing up
Seemingly simple migrations are dangerous and when executed incorrectly can lead to errors and downtimes. Each should be planned and carried out in such a way that the system is available all the time. What’s more, run migrations should be reversible. It means that, if there appears any errors, we should be able to rollback these changes, restoring system stability.