Elixir code used in migrations can cause troubles when we decide to start up our system with an empty database. To understand the problem, let’s take the same example as the one used in my previous article entitled “How to migrate live production data”.
Each year, triathlon races are held in many countries. Triathletes from around the world can sign up for one of 4 distances.
defmodule Triathlon.Race do
use Ecto.Schema
schema "triathlon_races" do
field :limit, :integer
field :distance, :string
# a bunch of other fields
end
def sign_up(race_id, user_id) do
Repo.transaction(fn ->
race = fetch_exclusively(race_id)
case any_entry_available?(race) do
true -> add_participant(race, user_id)
false -> {:error, "All entries have been sold out."}
end
end)
end
defp any_entry_available?(%Race{
id: race_id,
limit: limit
}) do
signed_up_number = fetch_participants_number(race_id)
limit > signed_up_number
end
end
defmodule Triathlon.Participant do
use Ecto.Schema
schema "triathlon_participants" do
field :user_id, :integer
field :race_id, :integer
# a bunch of other fields
end
end
Notice that every time someone tries to register, we have to fetch the participant count. We also have to use a lock to prevent race conditions. This can be slow when many people try to register at the same time.
To solve that, we decide to add a new field with confusing name entries.
defmodule Migrations.AddCounterCacheOnTriathlonRaces do
use Ecto.Migration
import Ecto.Query
def change do
alter table(:triathlon_races) do
add :entries, :integer
end
end
Triathlon.Race
|> Repo.all()
|> Enum.each(fn race ->
participants_number =
Triathlon.Participant
|> where([participant], participant.race_id == ^race.id)
|> Repo.aggregate(:count, :id)
entries = race.limit - participants_number
race
|> Ecto.Changeset.change(%{entries: entries})
|> Repo.update()
end)
end
While signing up for a race, we can check the left entries based on the triathlon_races table. When a user successfully registers, the number of available entries decreases.
defmodule Triathlon.Race do
# a bunch of other logic
def sign_up(race_id, user_id) do
Repo.transaction(fn ->
race = fetch_exclusively(race_id)
case any_entry_available?(race) do
true -> add_participant(race, user_id)
false -> {:error, "All entries have been sold out."}
end
end)
end
defp any_entry_available?(%{entries: entries}) do
entries > 0
end
defp sign_up(race, user_id) do
# a bunch of other logic
Race
|> Ecto.Changeset.change(%{
available_entries: race.entries - 1
})
|> Repo.update()
end
end
After a few months, we got confused whether the entries field represented the number of entries which either remained or were already sold. To make this field explicit, its name is changed to entries_left.
defmodule Migrations.ChangeEntriesFieldOnTriathlonRaces do
use Ecto.Migration
def change do
rename table(:triathlon_races), :entries, to: :entries_left
end
end
defmodule Triathlon.Race do
use Ecto.Schema
schema "triathlon_races" do
field :limit, :integer
field :distance, :string
field :entries_left, :integer
# a bunch of other fields
end
end
The code is more understandable now. Success!
What could go wrong?
Let’s wonder what will happen if we run these all migrations on an empty database.
Every migration will be executed one by one, by the time the system meets the migration with the Elixir code.
In the moment of running this migration our schema looks as follows:
defmodule Triathlon.Race do
use Ecto.Schema
schema "triathlon_races" do
field :limit, :integer
field :distance, :string
field :entries_left, :integer
# a bunch of other fields
end
end
We don’t have our entries field anymore. It has been changed for entries_left.
Execution of the Elixir code in the migration will fail and return error as there are no entries key in the triathlon_races schema.
The project’s setup is destroyed and until we remove the Elixir code from the migration, the system won’t start up.
How to solve it?
One way to avoid such implications is to use pure SQL in migrations instead of writing code in Elixir.
Both approaches, theoretically, do the same. Notwithstanding, there is a small difference between them.
SQL query uses a database structure with such a version of it which exists in the moment of executing migration. The code always uses the most recent version of the database schema.
As you can see on the diagram below, the database’s structure changes along with the running migrations. The Elixir code is always the same during that process.
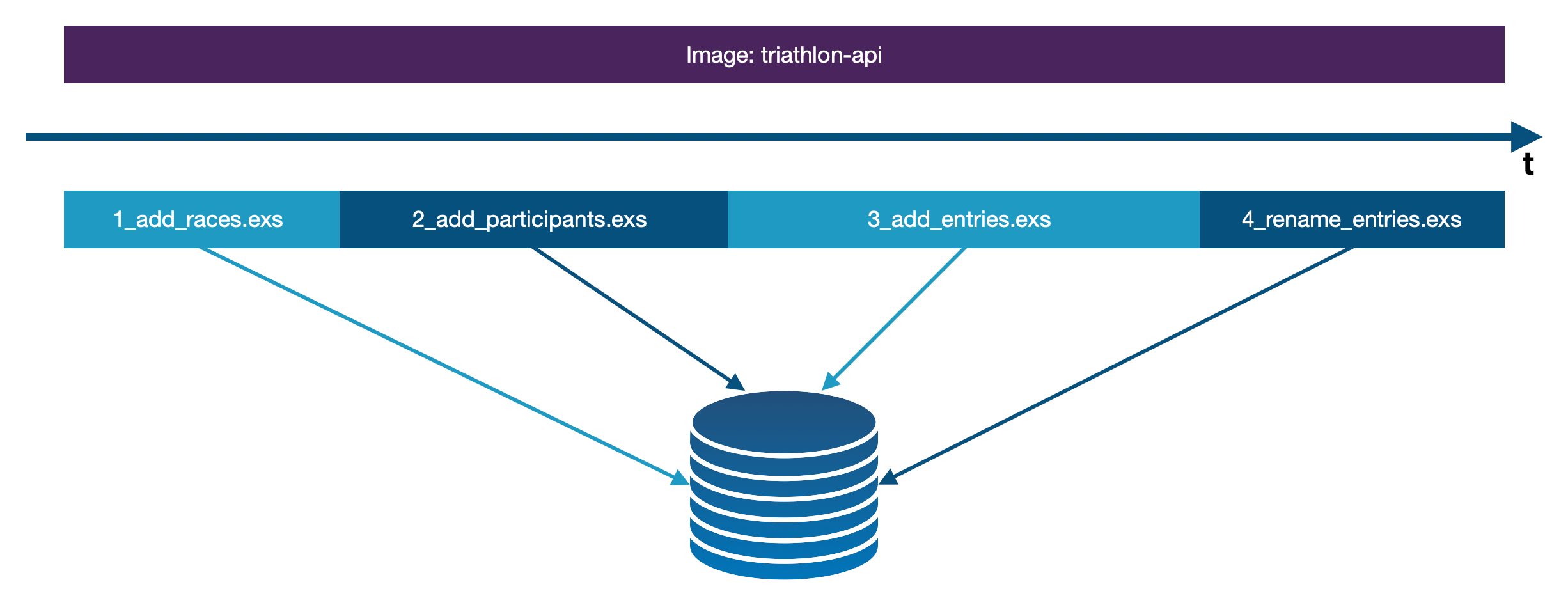
Such migration with SQL query can look like the one below:
defmodule Migrations.AddCounterCacheOnTriathlonRaces do
use Ecto.Migration
def change do
alter table(:triathlon_races) do
add :entries, :integer
end
execute("""
UPDATE triathlon_races
SET entries = triathlon_races.limit - participants_subquery.number
FROM (
SELECT race_id, count(*) AS number
FROM triathlon_participants
GROUP BY race_id
) AS participants_subquery
WHERE triathlon_races.id = participants_subquery.race_id;
""")
end
end
Problem solved! Now, if we change code in the project and then start up it from scratch, it won’t cause any troubles as the migrations rely only on a database’s structure.
SUM UP
It’s worth remembering that migrations are an immutable log of changes. These adjustments should always give the same effect. Some serious problems may arise, when references to code, which can be amended in every moment, appear in that changes log. Suddenly, the migration written some months ago uses stale code from that period instead of the new one which is currently in a project.