To guarantee zero downtime deployment, while deploying a new version of our application on more than one node, we can use rolling updates. What if this new version has a migration which renames either column or table? Will rolling updates protect our application against downtime?
Let’s assume that we have a users table. As the name is not clear, we have decided to rename it to participants, as we keep there records of people who signed up for a triathlon race.
defmodule Migrations.RenameUsersTable do
use Ecto.Migration
rename table(:users), to: table(:participants)
end
defmodule Participants do
use Ecto.Schema
schema "participants" do
...
end
end
Not only did we write a migration which renames table, but also changed both the module and schema name.
Now, let’s deploy this new code for both instances of our application using rolling update.
It means that its version will be updated incrementally. The first instance will be terminated and replaced with the new version of the application. Afterwards, if the first instance starts up properly, then the second instance will be terminated and also replaced with the new one.
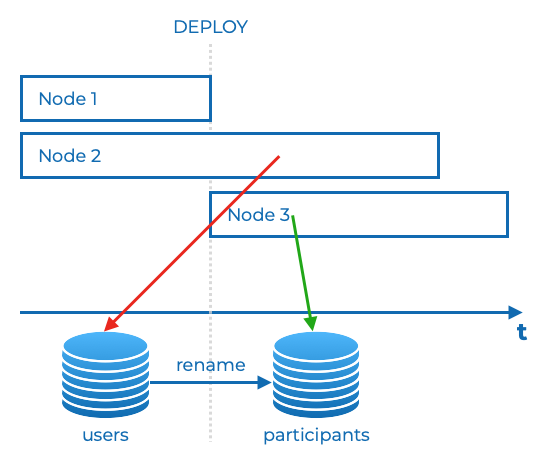
As you can see, there is a moment, before the second instance is replaced with the new one, when we have two versions of the application.
Both of them can be used by users. The first new instance ran the migration which renamed a table from users to participants and started using a new schema name - participant. Both instances of the application use the same database. Due to that, until the second instance is replaced, every request handled by it will return error as this instance uses the old schema name - users. The one which does not exist anymore in our database structure.
How can we solve that?
One way to solve the above-mentioned problem is to use PostgreSQL views. In simple terms, a PostgreSQL view gives us a possibility to create a query and assign it a name. To make it clearer, I’ll give an example in a moment.
Previously, while deploying the new version of our application, the change contained the migration which renames the table from users to participants. In this migration we can also create the following PostgreSQL view:
defmodule Migrations.RenameUsersTable do
use Ecto.Migration
rename table(:users), to: table(:participants)
execute("
CREATE VIEW users AS SELECT * FROM participants;
")
end
The query which fetches all records from table participants, which we’ve just renamed, has been assigned users name - the old table name. It means that from now both instances of the application can fetch everything from this table using both users and participants name, so the new table name and the old one.
If our application starts up properly and all the instances will be replaced with the new one, we can create another migration which drops this PostgreSQL view, as it won’t be required anymore.
defmodule Migrations.DropViewOnUsersTable do
use Ecto.Migration
execute("
DROP VIEW users;
")
end
What about changing the column name?
Assuming that we deploy the application on two instances, we will face the same problem once we run a migration which renames the column on the first instance. The same problem as the one with changing a table name. The second instance, which hasn’t been replaced yet with the new one containing new code, will use the old column name - the one which doesn’t exist anymore in the database.
What can we do about it?
Do not rename the column - write a migration which creates a new one. Do all the steps which I described in my previous article entitled “How to migrate live production data” in order to implement these changes without any downtime.